
There’s a lot to know about search intent, from using deep learning to infer search intent by classifying text and breaking down SERP titles using Natural Language Processing (NLP) techniques, to clustering based on semantic relevance with the benefits explained.
Not only do we know the benefits of deciphering search intent — we have a number of techniques at our disposal for scale and automation, too.
But often, those involve building your own AI. What if you don’t have the time nor the knowledge for that?
In this column, you’ll learn a step-by-step process for automating keyword clustering by search intent using Python.
Advertisement
Continue Reading Below
SERPs Contain Insights for Search Intent
Some methods require that you get all of the copy from titles of the ranking content for a given keyword, then feed it into a neural network model (which you have to then build and test), or maybe you’re using NLP to cluster keywords.
There is another method that enables you to use Google’s very own AI to do the work for you, without having to scrape all the SERPs content and build an AI model.
Let’s assume that Google ranks site URLs by the likelihood of the content satisfying the user query in descending order. It follows that if the intent for two keywords is the same, then the SERPs are likely to be similar.
Advertisement
Continue Reading Below
For years, many SEO professionals compared SERP results for keywords to infer shared (or shared) search intent to stay on top of Core Updates, so this is nothing new.
The value-add here is the automation and scaling of this comparison, offering both speed and greater precision.
How to Cluster Keywords by Search Intent at Scale Using Python (With Code)
Begin with your SERPs results in a CSV download.
1. Import the list into your Python notebook.
import pandas as pd
import numpy as np
serps_input = pd.read_csv('data/sej_serps_input.csv')
serps_input
Below is the SERPs file now imported into a Pandas dataframe.
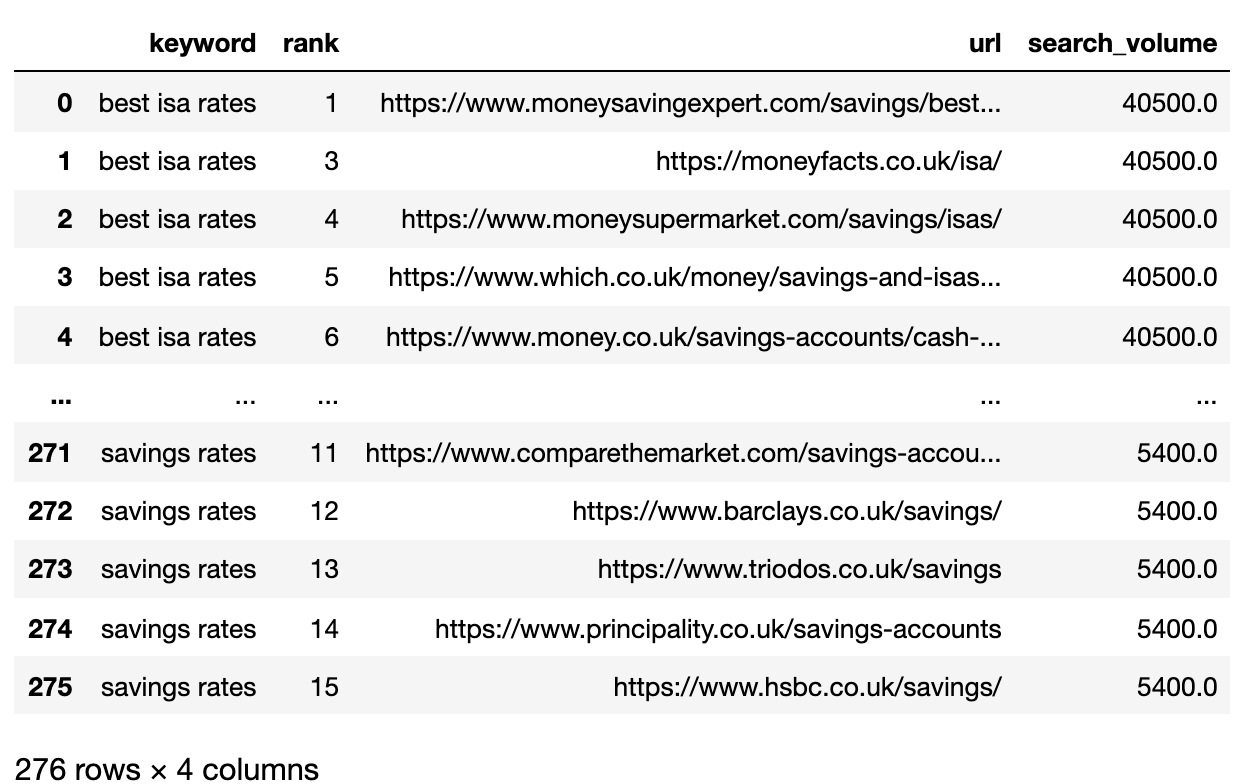
2. Filter Data for Page 1
We want to compare the Page 1 results of each SERP between keywords.
We’ll split the dataframe into mini keyword dataframes to run the filtering function before recombining into a single dataframe, because we want to filter at keyword level:
# Split
serps_grpby_keyword = serps_input.groupby("keyword")
k_urls = 15
# Apply Combine
def filter_k_urls(group_df):
filtered_df = group_df.loc[group_df['url'].notnull()]
filtered_df = filtered_df.loc[filtered_df['rank'] <= k_urls]
return filtered_df
filtered_serps = serps_grpby_keyword.apply(filter_k_urls)
# Combine
## Add prefix to column names
#normed = normed.add_prefix('normed_')
# Concatenate with initial data frame
filtered_serps_df = pd.concat([filtered_serps],axis=0)
del filtered_serps_df['keyword']
filtered_serps_df = filtered_serps_df.reset_index()
del filtered_serps_df['level_1']
filtered_serps_df
3. Convert Ranking URLs to a String
Because there are more SERP result URLs than keywords, we need to compress those URLs into a single line to represent the keyword’s SERP.
Here’s how:
# convert results to strings using Split Apply Combine
filtserps_grpby_keyword = filtered_serps_df.groupby("keyword")
def string_serps(df):
df['serp_string'] = ''.join(df['url'])
return df
# Combine
strung_serps = filtserps_grpby_keyword.apply(string_serps)
# Concatenate with initial data frame and clean
strung_serps = pd.concat([strung_serps],axis=0)
strung_serps = strung_serps[['keyword', 'serp_string']]#.head(30)
strung_serps = strung_serps.drop_duplicates()
strung_serps
Below shows the SERP compressed into a single line for each keyword.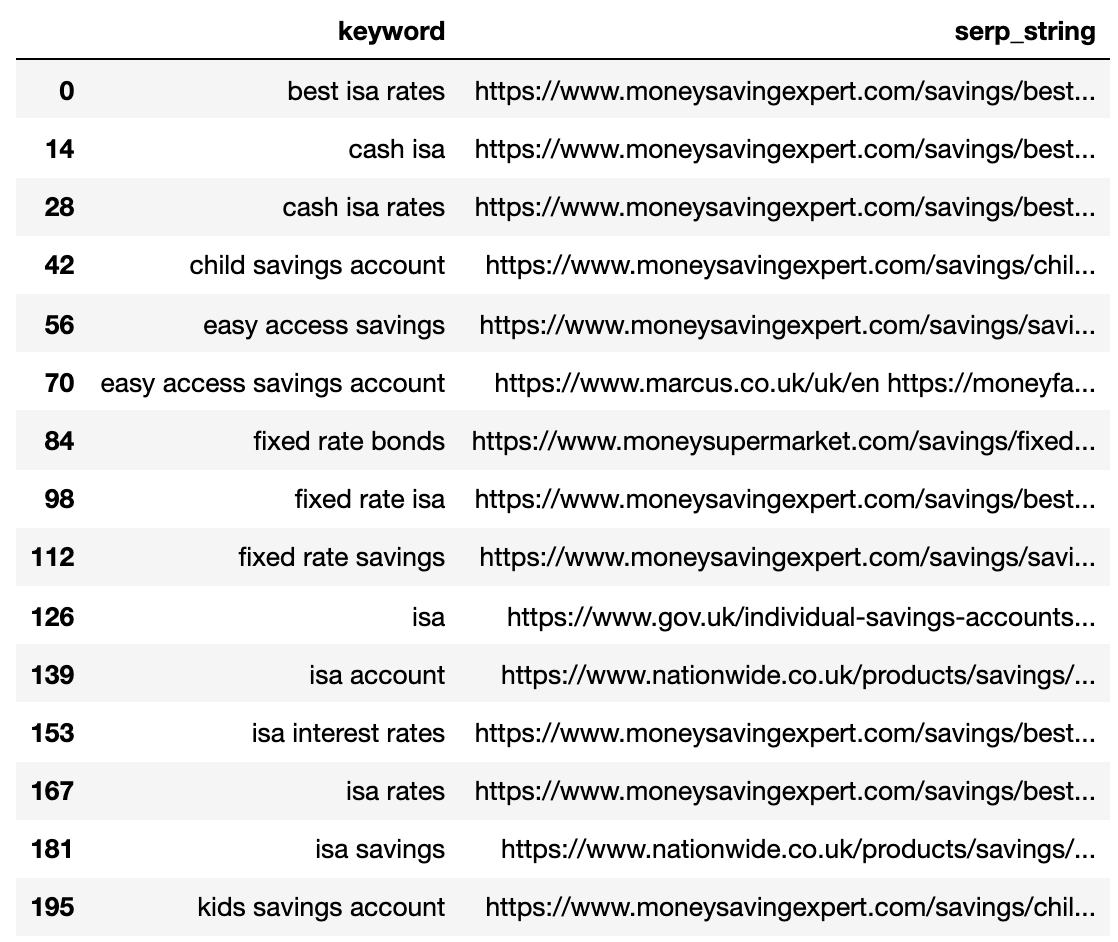
4. Compare SERP Similarity
To perform the comparison, we now need every combination of keyword SERP paired with other pairs:
Advertisement
Continue Reading Below
# align serps
def serps_align(k, df):
prime_df = df.loc[df.keyword == k]
prime_df = prime_df.rename(columns = "serp_string" : "serp_string_a", 'keyword': 'keyword_a')
comp_df = df.loc[df.keyword != k].reset_index(drop=True)
prime_df = prime_df.loc[prime_df.index.repeat(len(comp_df.index))].reset_index(drop=True)
prime_df = pd.concat([prime_df, comp_df], axis=1)
prime_df = prime_df.rename(columns = "serp_string" : "serp_string_b", 'keyword': 'keyword_b', "serp_string_a" : "serp_string", 'keyword_a': 'keyword')
return prime_df
columns = ['keyword', 'serp_string', 'keyword_b', 'serp_string_b']
matched_serps = pd.DataFrame(columns=columns)
matched_serps = matched_serps.fillna(0)
queries = strung_serps.keyword.to_list()
for q in queries:
temp_df = serps_align(q, strung_serps)
matched_serps = matched_serps.append(temp_df)
matched_serps

The above shows all of the keyword SERP pair combinations, making it ready for SERP string comparison.
There is no open source library that compares list objects by order, so the function has been written for you below.
Advertisement
Continue Reading Below
The function ‘serp_compare’ compares the overlap of sites and the order of those sites between SERPs.
import py_stringmatching as sm
ws_tok = sm.WhitespaceTokenizer()
# Only compare the top k_urls results
def serps_similarity(serps_str1, serps_str2, k=15):
denom = k+1
norm = sum([2*(1/i - 1.0/(denom)) for i in range(1, denom)])
ws_tok = sm.WhitespaceTokenizer()
serps_1 = ws_tok.tokenize(serps_str1)[:k]
serps_2 = ws_tok.tokenize(serps_str2)[:k]
match = lambda a, b: [b.index(x)+1 if x in b else None for x in a]
pos_intersections = [(i+1,j) for i,j in enumerate(match(serps_1, serps_2)) if j is not None]
pos_in1_not_in2 = [i+1 for i,j in enumerate(match(serps_1, serps_2)) if j is None]
pos_in2_not_in1 = [i+1 for i,j in enumerate(match(serps_2, serps_1)) if j is None]
a_sum = sum([abs(1/i -1/j) for i,j in pos_intersections])
b_sum = sum([abs(1/i -1/denom) for i in pos_in1_not_in2])
c_sum = sum([abs(1/i -1/denom) for i in pos_in2_not_in1])
intent_prime = a_sum + b_sum + c_sum
intent_dist = 1 - (intent_prime/norm)
return intent_dist
# Apply the function
matched_serps['si_simi'] = matched_serps.apply(lambda x: serps_similarity(x.serp_string, x.serp_string_b), axis=1)
serps_compared = matched_serps[['keyword', 'keyword_b', 'si_simi']]
serps_compared

Now that the comparisons have been executed, we can start clustering keywords.
Advertisement
Continue Reading Below
We will be treating any keywords which have a weighted similarity of 40% or more.
# group keywords by search intent
simi_lim = 0.4
# join search volume
keysv_df = serps_input[['keyword', 'search_volume']].drop_duplicates()
keysv_df.head()
# append topic vols
keywords_crossed_vols = serps_compared.merge(keysv_df, on = 'keyword', how = 'left')
keywords_crossed_vols = keywords_crossed_vols.rename(columns = 'keyword': 'topic', 'keyword_b': 'keyword',
'search_volume': 'topic_volume')
# sim si_simi
keywords_crossed_vols.sort_values('topic_volume', ascending = False)
# strip NANs
keywords_filtered_nonnan = keywords_crossed_vols.dropna()
keywords_filtered_nonnan
We now have the potential topic name, keywords SERP similarity, and search volumes of each.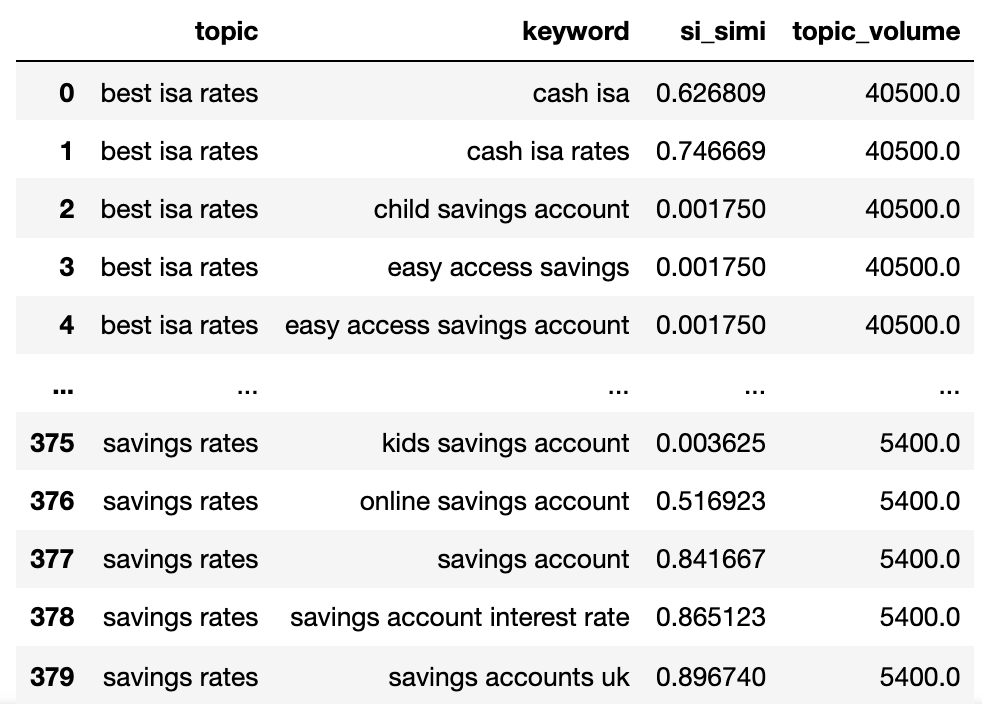
You’ll note that keyword and keyword_b have been renamed to topic and keyword, respectively.
Advertisement
Continue Reading Below
Now we’re going to iterate over the columns in the dataframe using the lamdas technique.
The lamdas technique is an efficient way to iterate over rows in a Pandas dataframe because it converts rows to a list as opposed to the .iterrows() function.
Here goes:
queries_in_df = list(set(keywords_filtered_nonnan.topic.to_list()))
topic_groups_numbered =
topics_added = []
def find_topics(si, keyw, topc):
i = 0
if (si >= simi_lim) and (not keyw in topics_added) and (not topc in topics_added):
i += 1
topics_added.append(keyw)
topics_added.append(topc)
topic_groups_numbered[i] = [keyw, topc]
elif si >= simi_lim and (keyw in topics_added) and (not topc in topics_added):
j = [key for key, value in topic_groups_numbered.items() if keyw in value]
topics_added.append(topc)
topic_groups_numbered[j[0]].append(topc)
elif si >= simi_lim and (not keyw in topics_added) and (topc in topics_added):
j = [key for key, value in topic_groups_numbered.items() if topc in value]
topics_added.append(keyw)
topic_groups_numbered[j[0]].append(keyw)
def apply_impl_ft(df):
return df.apply(
lambda row:
find_topics(row.si_simi, row.keyword, row.topic), axis=1)
apply_impl_ft(keywords_filtered_nonnan)
topic_groups_numbered = k:list(set(v)) for k, v in topic_groups_numbered.items()
topic_groups_numbered
Below shows a dictionary containing all the keywords clustered by search intent into numbered groups:
1: ['fixed rate isa', 'isa rates', 'isa interest rates', 'best isa rates', 'cash isa', 'cash isa rates'], 2: ['child savings account', 'kids savings account'], 3: ['savings account', 'savings account interest rate', 'savings rates', 'fixed rate savings', 'easy access savings', 'fixed rate bonds', 'online savings account', 'easy access savings account', 'savings accounts uk'], 4: ['isa account', 'isa', 'isa savings']
Let’s stick that into a dataframe:
topic_groups_lst = []
for k, l in topic_groups_numbered.items():
for v in l:
topic_groups_lst.append([k, v])
topic_groups_dictdf = pd.DataFrame(topic_groups_lst, columns=['topic_group_no', 'keyword'])
topic_groups_dictdf
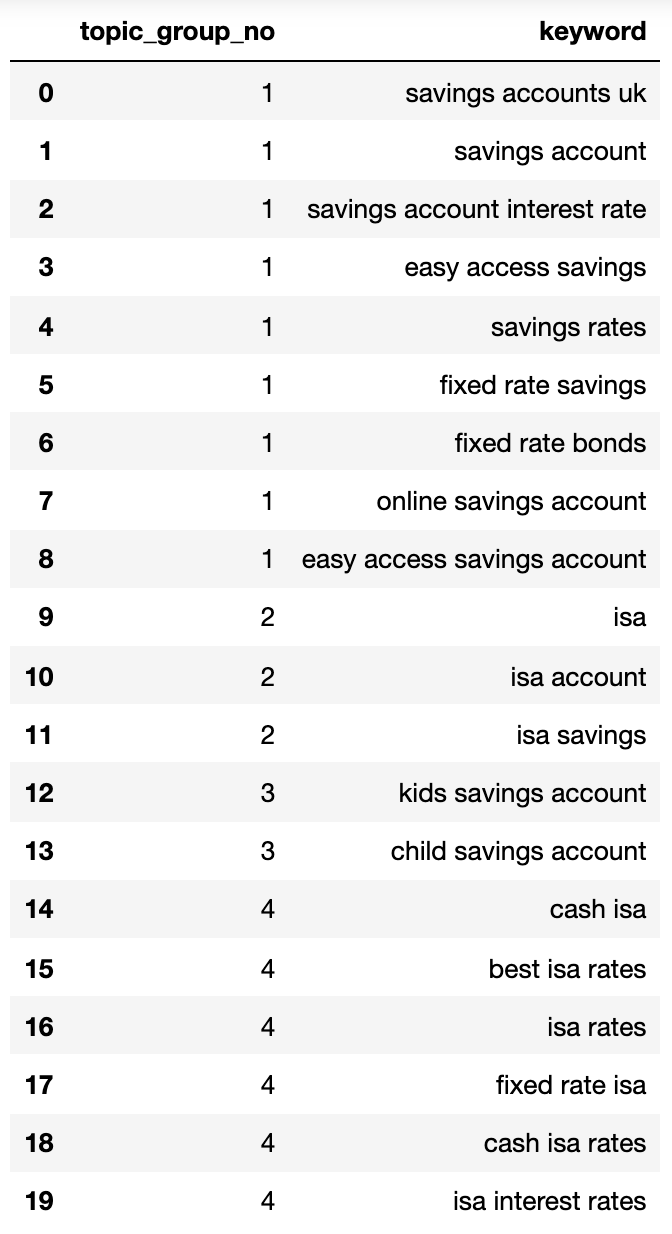
The search intent groups above show a good approximation of the keywords inside them, something that an SEO expert would likely achieve.
Advertisement
Continue Reading Below
Although we only used a small set of keywords, the method can obviously be scaled to thousands (if not more).
Activating the Outputs to Make Your Search Better
Of course, the above could be taken further using neural networks processing the ranking content for more accurate clusters and cluster group naming, as some of the commercial products out there already do.
For now, with this output you can:
- Incorporate this into your own SEO dashboard systems to make your trends and SEO reporting more meaningful.
- Build better paid search campaigns by structuring your Google Ads accounts by search intent for a higher Quality Score.
- Merge redundant facet ecommerce search URLs.
- Structure a shopping site’s taxonomy according to search intent instead of a typical product catalog.
Advertisement
Continue Reading Below
I’m sure there are more applications that I haven’t mentioned — feel free to comment on any important ones that I’ve not already mentioned.
In any case, your SEO keyword research just got that little bit more scalable, accurate, and quicker!
More Resources:
Image Credits
Featured image: Astibuag/Shutterstock.com
All screenshots taken by author, July 2021
Advertisement
Continue Reading Below



More Stories
SEO Service: From Keywords to Conversions
How SEO Service Boosts Website Traffic and Visibility
Essential Elements of a Winning SEO Service